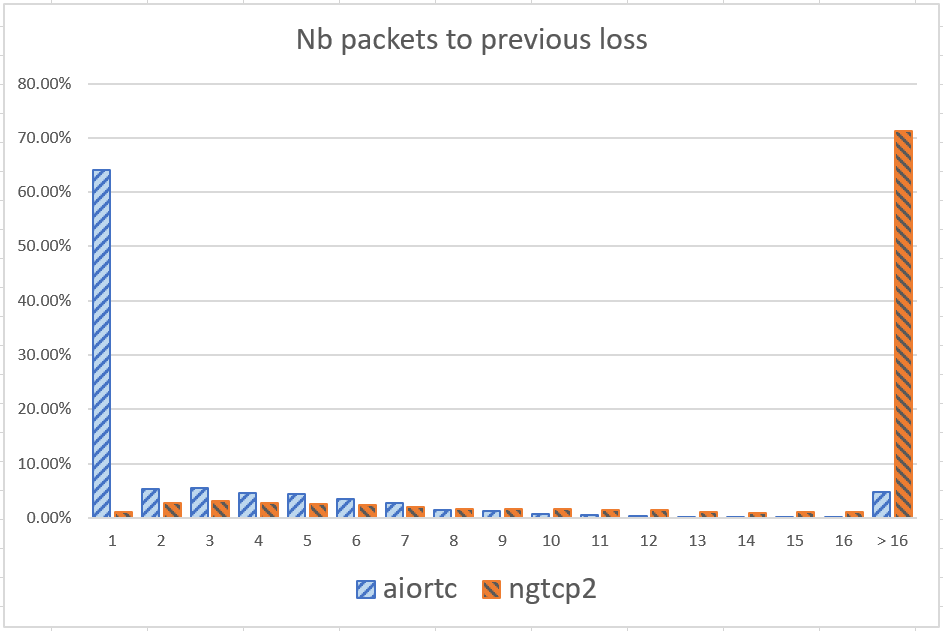
A week ago, I wrote a blog about the value of gathering QUIC logs (qlog) and processing them to derive statistics and better understand how the protocol interacts in practice with networks. My example was an analysis of packet losses. In many logs packet losses appeared to not happen as isolated random incidents, but rather as “trains” of successive errors. I have gathered more logs since and see that while this is true for some servers, it is not true for others. The new data from “quic.aiortc.org” confirms the correlation of errors, but the data from “nghttp2.org” does not show it.
This is not unexpected. Differences in local conditions and in server software cause differences in observations. The data is gathered from test servers, interacting with different testing clients. For example, the data set from “nghttp2.org” includes a lot of connections with short round trip times, from locations near the server. Getting more data from more servers would probably show still different sets of patterns. Data from user generated traffic would be useful, but servers will not provide it before we address privacy issues.
Full QUIC logs will reveal IP addresses of clients and servers, names of servers, times and parameters of connection, the length of downloaded documents, and QUIC parameters like connection identifiers. Incidental data might reveal names of documents, and maybe part of their contents. Logs may also contain information messages and error messages, which themselves might contain information about clients and servers.
One approach would be to build an automated “log scrubber” that would “clean” the logs, so the cleaned archives could be used for research without causing privacy issues. This requires examining all the data elements and deciding whether they can to be archived as is, whether they need to be anonymized before archiving, or whether they need to be simply deleted. For example, contents and names of documents should probably be removed from the long-term archives. Headers of packets and acknowledgement frames should probably be kept. Connection identifiers should probably be anonymized to enable correlation between client and server logs without allowing tracking of users.
The good news is that the QLOG specification allows easy parsing of the logs, and thus easy implementation of an efficient scrubber. But before that, we need to achieve a consensus on a “log privacy” requirement. I just gave a examples of log elements for which consensus appears reasonably easy to reach, but these are the easy ones. In the end, I can see the privacy specification being almost as long as the QUIC specification itself! But let us not lose sight of the goal. Big companies have private access to large amount of data and use it to improve their products. Independent researchers need enough publicly available data to compete. And they will only get that if we solve the privacy issues.